
The Kadena Light Client (LC) provides a streamlined and efficient way to verify blockchain state transitions and proofs without needing to store or synchronize the entire blockchain.
The following documentation aims to provide a high-level overview of the Kadena LC and its components, along with a guide on how to set up and run or benchmark the Kadena LC.
Note
The following documentation has been written with the supposition that the reader is already knowledgeable about the Chainweb protocol and the Kadena blockchain.
To read about it refer to the whitepapers, the documentation and the
chainweb-noderepository wiki.It is also required that the reader is familiar with Simple Payment Verification (SPV). They can refer to the Bitcoin whitepaper for more information.
Sections
An overview of what is the Light Client and the feature set it provides.
A detailed description of the components that make up the Light Client.
A guide on how to set up and run the Light Client.
A guide on how to benchmark the Light Client.
Design of the Light Client
Light clients can be seen as lightweight nodes that enable users to interact with the blockchain without needing to download the entire blockchain history. They rely on full nodes to provide necessary data, such as block headers, and use cryptographic proofs to verify transactions and maintain security.
Info
In the current implementation of the Light Client, we consider the whole Chainweb protocol as a single chain. This is a simplification that allows us to create the notion of layer blocks as blocks containing the block headers for all the chains in the network at a given height.
At the core of the LC there are two proofs:
- Prove the current longest chain on top of the Chainweb Protocol to ensure that the light client is in sync with the running chain.
- Prove the verification for an SPV at the tip of the longest finalized chain to bridge a state transition.
This is implemented by two proofs, one for each statement. The light client verifier needs to keep track of the most recent verified layer block headers to be able to continuously verify on top of the longest chain. For security reasons, a threshold on the work to be produced on top of a layer block is set to ensure that the light client is not tricked into verifying a chain that is not the longest chain.
We keep a list of the most recent layer block headers that have been verified by the light client to handle forks that could happen on the Chainweb protocol.
The first proof needs to be generated to ensure that the light client is in sync with the longest chain.
The second proof is generated and submitted when a proof about some on-chain value is required, for example when a deposit to some account needs to be validated. It has to be noted that it also ratchet the verifier state closer to the longest chain state.
The current Verifying Key Hashes which uniquely identify the specific RISC-V binaries for the proof programs, located in the
kadena/kadena-programs/artifacts/
directory are:
longest_chain:0x00b35a3df67c07d7095db4e5744a9f3f93b6c7526c5b380b1d380b1cf5f5f4a8spv:0x0056c9dcde9d2c9465f5f310944248f4fa9b7797158165598f35a80f3d3a8411
These values are also present in and used by the solidity fixtures.
Longest chain proof
The light client needs to keep track of the longest chain to ensure that it is in sync with the running chain. The longest chain is the chain with the most accumulated work.
There are a few predicates that need to be satisfied to ensure that the light client is in sync with the longest chain:
- The newly presented list of blocks supposed to represent the tip of the longest chain must be mined on top of an already verified layer block.
- The height of each layer block must be strictly increasing.
- The parent hash of each inner chain block headers must match the hash of the previous block of the given chain ID.
- The work produced for a given chain block header must be inferior or equal to the current target set for the chain.
- The list of blocks representing the new tip of the longest chain must contain a block with a threshold of work produced on top of it satisfying an arbitrary value set by the Light Client.
- The chain block headers composing the layer block headers are properly braided, meaning that each chain block header contains information of their adjacent chain block headers.
- If the one of the block in the list represents a new epoch, check that the difficulty adjustment is correct.
To ensure that the predicates 1. and 5. the Light Client verifier needs to keep track of the most recent verified layer block headers and an arbitrary security threshold to consider a block as the tip of the longest chain.
Longest Chain program IO
Inputs
The following data structures are required for proof generation:
- Vector of
LayerBlockHeader: A List of layer block headers that can be considered as part of the longest chain.- Element at index 0: An already verified Layer Block Header.
Outputs
BigInt: U256 representing the total work produced on top of the newly verified block.HashValue: 32 bytes representing the hash of the first layer block header of the list.HashValue: 32 bytes representing the hash of the newly verified layer block header.
SPV proof
The Simplified Payment Verification (SPV) proof is a cryptographic proof that allows the light client to verify that a transaction has been included in a block. The SPV proof is generated by the full node and sent to the light client. The light client can then verify the proof and trust that the transaction has been included in the block.
The light client fetches the SPV proof through the /spvendpoint
of the full node.
Along with the verification of the SPV the programs, the predicates for the longest chain proof are also verified to ensure that the light client is in sync with the running chain.
SPV program IO
Inputs
The following data structures are required for proof generation:
- Vector of
LayerBlockHeader: A List of layer block headers that can be considered as part of the longest chain.- Element at index 0: An already verified Layer Block Header.
- SPV: An SPV proof produced for a chain at the height of the newly verified layer block header.
HashValue: 32 bytes representing the hash of the expected block header of the SPV proof.
Outputs
BigInt: U256 representing the total work produced on top of the newly verified block.HashValue: 32 bytes representing the hash of the first layer block header of the list.HashValue: 32 bytes representing the hash of the newly verified layer block header.HashValue: 32 bytes representing the hash of the subject of the SPV proof.
Security considerations
Sphinx
The Sphinx prover is a fork of SP1
and as such inherits a lot from its security design. The current release of Sphinx (dev) has backported all the
upstream security fixes as of SP1 v1.0.8-testnet. We will continue to update Sphinx with backports of upstream
security fixes and subsequent updates to both Sphinx and the Light Client, making them available as hotfixes.
In terms of Sphinx-specific changes that require special attention, here is a non-exhaustive list of Sphinx AIR chips used for precompiles that are either not present in upstream SP1, or have had non-trivial changes:
Blake2sRoundChip: Chip for the Blake2s hash function compression, as specified in RFC 7693.Sha512CompressChip,Sha512ExtendChip: Chips for the SHA-512 hash function compression.
Notably, the Kadena light client does not use BLS12-381 related precompiles, such as field operations (FieldAddChip, FieldSubChip, FieldMulChip) or G1 decompression (Bls12381G1DecompressChip), neither does it use Secp256k1DecompressChip, a chip for decompressing K256 compressed points. Therefore, the light client’s proof does not depend on the correctness of these precompiles.
There are also some SP1 chips and precompiles that are not present in Sphinx, such as Uint256MulChip.
Architecture components
Light clients can be seen as lightweight nodes that enable users to interact with the blockchain without needing to download the entire blockchain history. They rely on full nodes to provide necessary data, such as block headers, and use cryptographic proofs to verify transactions and maintain security.
There are three core components that need to exist to have a functional light client bridge running:
- Source Chain Node: A full node of the source chain from which it is possible to fetch the necessary data to generate our proofs.
- Coordinator Middleware: This middleware is responsible for orchestrating the other components that are part of the architecture.
- Light Client Proving Servers: The core service developed by ACC. It contains all the necessary logic to generate the necessary proofs and exposes it through a simple RPC endpoint.
- Verifier: A software that can verify the proofs generated by the Light Client. This verification can happen in a regular computer, using a Rust verifier exposed by the Proof servers, or it can be implemented as a smart contract living on a destination chain.
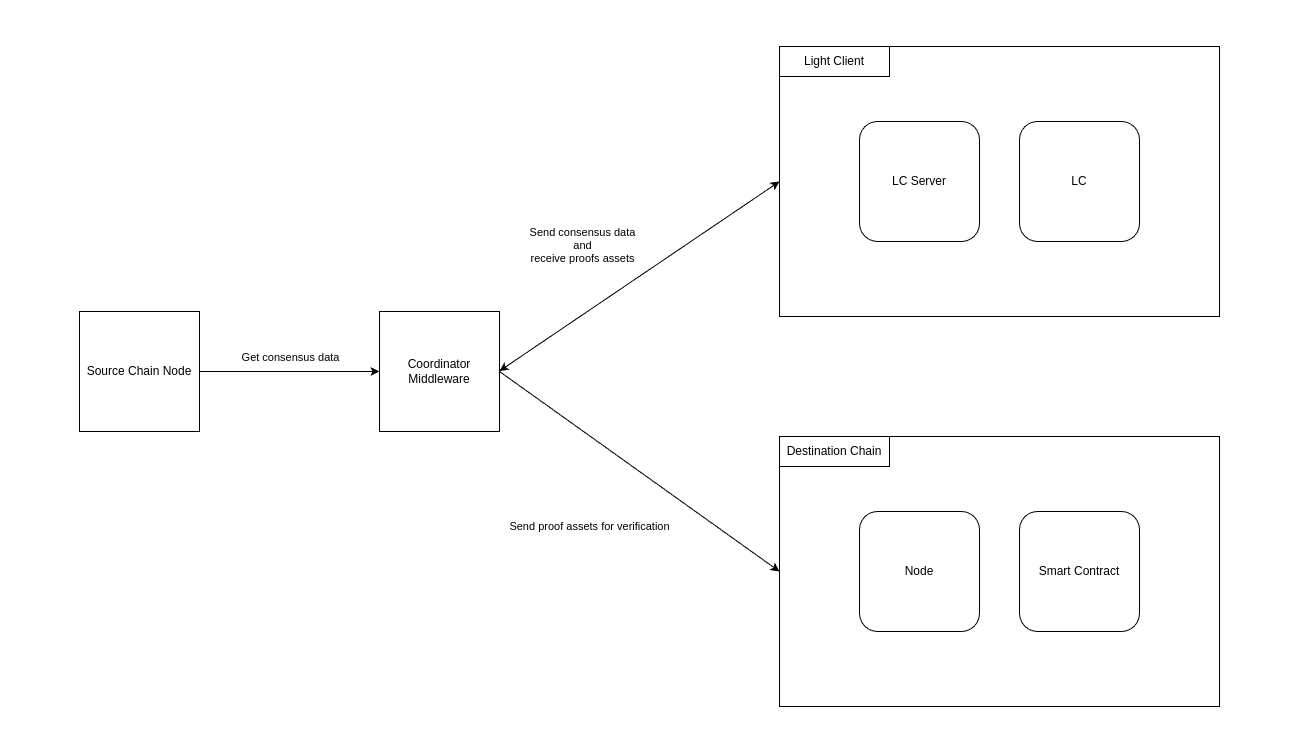
Kadena Node
In order to generate the two proofs composing the Light Client, it is needed to fetch data from the Kadena network. To retrieve this data, the Light Client needs to interact with a node from the Kadena chain.
Kadena Full Node
The connection to a Kadena Full Node is necessary to access the endpoint we require to fetch the data we use as input for our proofs. The following endpoints are currently leverage:
/header: Endpoint used to fetch the chain block headers that will be composing the layer block headers we want to generate a proof about./payload/<PAYLOAD_HASH>/outputs: Endpoint used to fetch the request key for the transaction we want to verify an SPV about./pact/spv: Endpoint used to request an SPV about a particular transaction.
Proof Server
The Proof Server is a component of the Light Client that is responsible for generating and serving proofs to the client. The server is designed to be stateless and can be scaled horizontally to handle a large number of requests. The Proof Server can be divided in two distinct implementations:
- Proof programs: The proof program contains the logic that will be executed by our Proof server, generating the succinct proof to be verified. The proof programs are run inside the Sphinx zkVM and prover.
- Server: The server is a layer added on top of the proving service that makes it available to external users via a simple protocol.
Proof programs
This layer of the Proof Server corresponds to the code for which the execution has to be proven. Its logic is the core
of our whole implementation and ensures the correctness of what we are trying to achieve. The programs are written in Rust
and leverages the argumentcomputer/sphinx zkVM to generate the proofs and verify them.
In the design document of both the Longest chain proof and the SPV proof, we describe what each program has to prove. Most computations performed by the proof programs are directed towards cryptographic operations, such as hashing values.
To accelerate those operations, we leverage some out-of-VM circuits called pre-compiles that are optimized for those specific operations. The following pre-compiles are used in our codebase:
- blake2s: A library for Blake2s hashing making use of pre-compiles for the compression function. Used while calculating the PoW hash for the chain block headers.
- sha2: A library for SHA-512 hashing making use of pre-compiles for the compression function. Used to calculate the block header hashes.
The code to be proven is written in Rust and then compiled to RISC-V binaries, stored in kadena/kadena-programs/artifacts/.
We then use Sphinx to generate the proofs and verify them based on those binaries. The generated proofs can be STARKs, which
are faster to generate but cannot be verified directly on-chain, or wrapped in a SNARK, which take longer to generate but can
be verified cheaply on-chain.
Server
The server is a layer added on top of the proving service that makes it available to external users. It is a simple REST server that is open to incoming connections on a port specified at runtime.
The server have two possible mode of operation:
- Single: The deployed server will handle all incoming proving and verifying requests.
- Split: The deployed server will handle only part of the requests, and will forward the rest to another server.
It is possible to generate and verify both STARK core proofs and SNARK proofs.
The RPC protocol used by the servers is a very simple bytes protocol passing serialized messages back and forth.
The messages are defined in light-client/src/types/network.rs.
See also the documentation on the client.
Client
The client is the coordinator of the Light Client. It is responsible for orchestrating the communication between the Proof Server and the Kadena nodes. In our current example implementation it can also serve as a drop-in replacement for what an on-chain verifier would be responsible for.
The client also demonstrates how to request data from the Kadena nodes endpoints, how to forward it to the proof servers using the simple binary RPC protocol, example and how to parse the received responses from the server. See the source for more details.
The client has two phases:
- Initialization: The client fetches the initial data from the Kadena node to set an initial state for itself and the verifier.
- Main Loop: The client listens for new data from the Kadena node and generates proofs for the verifier to verify. This includes new proofs for the longest chain and SPV.
Run the Light Client
In the previous section, we covered all the architecture components of the Light Client and explained their specific roles. In this section we will cover how to set them up and run the Light Client to start proving epoch change and inclusion proofs.
As the computational requirements for the Proof Server are heavy, here are the machine specs for each component, based on off-the-shelf machines from cloud providers:
| CPU | Memory (GB) | Disk Size (GB) | Example | |
|---|---|---|---|---|
| Client | 8 cores, 16 threads | 32 | 64 | GCP C3 |
| Proof Server | Intel x86_64 Sapphire Rapids, 128 vCPU, bare metal, supports avx512_ifma and avx512_vbmi2 | 1024 | 150 | AWS r7iz.metal-32xl |
Note
Generating a proof needs a minimum of 128GB, but does not make use of more than ~200GB of memory.
Configuration
To run the Proof Server and the Client there are a few requirements that needs to be followed on the host machine.
First, you need to install nightly Rust and Golang. You can find the installation instructions for Rust here and for Golang here.
Make sure to install nightly Rust, which is necessary for AVX-512 acceleration:
rustup default nightly
We pin the nightly Rust version in rust-toolchain.toml to prevent unknown future changes
to nightly from interfering with the build process. In principle however, any recent nightly release of Rust should
work.
Second, you need to install the cargo-prove binary.
- Install
cargo-provefrom Sphinx:
git clone https://github.com/argumentcomputer/sphinx.git && \
cd sphinx/cli && \
cargo install --locked --path .
- Install the toolchain. This downloads the pre-built toolchain from SP1
cd ~ && \
cargo prove install-toolchain
- Verify the installation by checking if
succinctis present in the output ofrustup toolchain list
Finally, there's a few extra packages needed for the build:
sudo apt update && sudo apt-get install -y build-essential libssl-dev pkg-config libudev-dev cmake
For non-Ubuntu/non-Debian based distros, make sure to install the equivalent packages.
Logging Configuration
The light client uses two logging systems:
- Rust logging via
tokio-tracing, configured through theRUST_LOGenvironment variable. See the tracing documentation for detailed configuration options. - Go logging for FFI calls, configured through the
SP1_GO_LOGenvironment variable.
To set a global log level (e.g. warn), configure both variables:
RUST_LOG=warn SP1_GO_LOG=warn cargo run ...
Valid log levels are: error, warn, info, debug, trace, off
Deploy the Proof Server
We have two components to deploy for the Proof Server to work as intended. The primary and the secondary server. There is no particular order in which they should be deployed, but here we will deploy the secondary and then the primary.
For best results, the primary and secondary servers should be deployed to different server instances, so that proof generation can happen in parallel if necessary.
Requirements
Make sure to finish the initial configuration first.
Environment variables
The environment variables to set for the Proof Server are explained in the following section.
Note
One can also set the
RUST_LOGenvironment variable todebugto get more information about the execution of the server.
Deploy the secondary server
Now that our deployment machine is properly configured, we can run the secondary server.
git clone https://github.com/argumentcomputer/zk-light-clients.git && \
cd zk-light-clients/kadena/light-client && \
RECONSTRUCT_COMMITMENTS=false SHARD_BATCH_SIZE=0 SHARD_CHUNKING_MULTIPLIER=64 SHARD_SIZE=4194304 RUSTFLAGS="-C target-cpu=native -C opt-level=3" cargo run --release --bin proof_server -- --mode "single" -a <NETWORK_ADDRESS>
Deploy the primary server
Finally, once the primary server is configured in the same fashion, run it:
git clone https://github.com/argumentcomputer/zk-light-clients.git && \
cd zk-light-clients/kadena/light-client && \
RECONSTRUCT_COMMITMENTS=false SHARD_BATCH_SIZE=0 SHARD_CHUNKING_MULTIPLIER=64 SHARD_SIZE=4194304 RUSTFLAGS="-C target-cpu=native -C opt-level=3" cargo run --release --bin proof_server -- --mode "split" -a <NETWORK_ADDESS> --snd-addr <SECONDARY_SERVER_ADDRESS>
Note
Logging can be configured via
RUST_LOGfor Rust logging andSP1_GO_LOGfor Go FFI logging. For example:RUST_LOG=debug SP1_GO_LOG=debug cargo run ...See the configuration documentation for more details.
Run the Client
To coordinate the communication to all the components, we need to run the Client. The Client will communicate each component to fetch the data and generate the proofs.
Requirements
Make sure to finish the initial configuration first.
Launch the Client
With our deployment machine properly configured, we can run the client.
The client can either work with STARK or SNARK proofs. To configure this, the
environment variable MODE can be set to either STARK or SNARK. The default is STARK.
git clone https://github.com/argumentcomputer/zk-light-clients.git && \
cd zk-light-clients/kadena && \
MODE=SNARK RUST_LOG="debug" cargo run -p light-client --release --bin client -- -c <KADENA_NODE_URL> -p <PROOF_SERVER_ADDRESS>
Info
An example of a public Kadena node URL for mainnet is
http://api.chainweb.com.
The client only needs to communicate with the primary proof server, since requests to the secondary server are automatically forwarded.
With this, the Client should run through its initialization process and then start making requests to both the Proof Server and the Kadena node, generating proofs as needed in a loop.
Operate the bridge
In the previous sections we have gone over the steps to setup each components that are available in the source of the repository so that they can start interacting with each other.
However, in a practical scenario, the client and verifier contracts will have to be adapted to the use case that a user wants to implement. We will go over the steps to adapt the components for any use case in this section.
Adapt the client
Initialize the client
Before we can start fetching data from the Kadena network, we need to initialize the client. To do so we need to select a block that we trust being at the tip of the longest chain. The logic to initialize the client is quite straight forward and an example implementation can be found in our mock client.
Fetch Kadena data
The first piece that will need some refactoring to adapt to a new use case is the client. The client should be considered as the main entry point for a bridge, and is responsible for fetching data from the Kadena network and submitting it to the prover.
The first key data needed for us to fetch are the necessary block headers to prove
that we are dealing with a block that can be considered the longest tip of the chain.
Basically the block we want to make this proof for has to be produced on top of an already
known block and have enough block power mined on top of it. The logic for
fetching the necessary headers in our codebase can be found in the get_layer_block_headers function..
This function leverages the /mainnet01/chain/{chain}/header from Kadena to
fetch the necessary headers from each chain. All the headers are then organized in a
Vec<ChainwebLayerHeader> where ChainwebLayerHeader is a struct representing
all the block headers for all chains at a given height.
The second important piece of data for our proofs are the data necessary to prove
an SPV. Such data can be easily retrieved from the /mainnet01/chain/{chain}/pact/spv
endpoint available from a Kadena node API. The chain parameter along with
the requestKey representing a transaction hash allow us to fetch an SPV for said
transaction. This particular API endpoint will return a SpvResponse struct
that has to be transformed to an Spv
struct to be passed to the prover. An example of this transformation can be found in the codebase.
Run the prover
The prover is quite straight forward to run. When ran in single mode, the only
parameter to properly set is the address it should listen to for incoming request.
It consists of a lightweight router that will listen to the following routes:
- (GET)
/health: Operationnal endpoint the returns a 200 HTTP code when the server is ready to receive requests - (GET)
/ready: Operationnal endpoint the returns a 200 HTTP code when the server is not currently handling a request - (POST)
/spv/proof: Endpoint to submit a proof request for an spv proof - (POST)
/spv/verify: Endpoint to submit a proof request for an spv proof verification - (POST)
/longest-chain/proof: Endpoint to submit a proof request for a longest chain proof - (POST)
/longest-chain/verify: Endpoint to submit a proof request for a longest chain proof verification
For proofs related endpoint the payload is a binary serialized payload that is sent over
HTTP. The Rust type in our codebase representing such types is Request.
The bytes payload format is the following:
Proof generation
| Name | Byte offset | Description |
|---|---|---|
| Request type | 0 | Type of the request payload |
| Proving mode | 1 | Type of the proof that the proof server should generate. 0 for STARK and 1 for SNARK |
| Proof inputs | 2 | Serialized inputs for the proof generation. Serialized LongestChainIn for longest chain and serialized SpvIn for spv. |
Proof verification
| Name | Byte offset | Description |
|---|---|---|
| Request type | 0 | Type of the request payload |
| Proof type | 1 | Type of the proof that the payload contains. 0 for STARK and 1 for SNARK |
| Proof | 2 | Bytes representing a JSON serialized SphinxProofWithPublicValues. |
The response bodies are more straight forward:
Proof generation
| Name | Byte offset | Description |
|---|---|---|
| Proof type | 0 | Type of the proof that the payload contains. 0 for STARK and 1 for SNARK |
| Proof | 1 | Bytes representing a JSON serialized SphinxProofWithPublicValues. |
Proof verification
| Name | Byte offset | Description |
|---|---|---|
| Successful proof verification | 0 | A 0 (fail) or 1 (success) byte value representing the success of a proof verification. |
Adapt the verifier
In the following section we will touch upon how a verifier contract has to be updated depending on a use case. However, it has to be kept in mind that some core data will have to be passed even thought some modifications have to be done for different use cases.
Core data
Note
The following documentation will be for SNARK proofs, as they are the only proofs that can be verified on our home chains.
The core data to be passed to any verification contrtact are the following:
- Verifying key: A unique key represented as 32 bytes, related to the program that is meant to be verified
- Public values: Serialized public values of the proof
- Proof: The serialized proof to be verified
Verifying key
The verifying key for a program at a given commit can be found in its fixture file
in the format of a hexified string prefixed by 0x. There is one file for the longest chain
program and one file for the spv program.
Public values
The public values and serialized proof data can be found through the type SphinxProofWithPublicValues
returned as an HTTP response body by the prover.
The public values can be found under the public_values property and are already
represented as a Buffer which data are to be transmitted to the verifier contract.
In the fixture files we leverage in our codebase, the public values are represented
as a hexified string prefixed by 0x.
Proof
The proof data to be passed to the verifier contract is the following:
| Name | Byte offset | Description |
|---|---|---|
| Verifying key prefix | 0 | Prefix to the encoded proof, a 4 bytes value corresponding to the first 4 bytes of the verifying key. |
| Encoded proof | 4 | Encoded proof which value can be found in the returned SNARK proof from the prover represented as SphinxProofWithPublicValues under proof.encoded_proof |
Example of the proof data extraction can be found in our fixture generation crate.
Wrapper logic
The wrapper logic refers to a smart contract wrapping the proof verification logic with the use case specific logic. It is needed to ensure that the verified proof corresponds to the expected data.
The logic to be executed in the wrapper contract will depend on the use case. However, there are some core logic that have to be executed for the longest chain and spv proof verification. The logic that has to be kept for the inclusion verification and the committee change program are showcased in our Solidity contracts (longest chain and spv).
The place where a user can add its own use case logic is where we currently print out some values for both the longest chain and spv).
Benchmark proving time
There are two types of benchmarks that can be used to get insight on the proving time necessary for each kind of proof generated by the proof server. The first type will generate STARK core proofs, and represents the time it takes to generate and prove execution of one of the programs. The second type will generate a SNARK proof that can be verified on-chain, and represents the end-to-end time it takes to generate a proof that can be verified directly on-chain. Due to the SNARK compression, the SNARK proofs take longer to generate and require more resources.
GPU acceleration
Currently, the Sphinx prover is CPU-only, and there is no GPU acceleration integrated yet. We are working on integrating future work for GPU acceleration as soon as we can to improve the overall proving time.
Configuration for the benchmarks
In this section we will cover the configuration that should be set to run the benchmarks. It is also important to run the benchmarks on proper machines, such as the one described for the Proof Server in the Run the Light Client section.
Requirements
The requirements to run the benchmarks are the same as the ones for the client. You will need to follow the instructions listed here.
Other settings
Here are the standard config variables that are worth setting for any benchmark:
-
RUSTFLAGS="-C target-cpu=native -C opt-level=3"This can also be configured in
~/.cargo/config.tomlby adding:[target.'cfg(all())'] rustflags = ["--cfg", "tokio_unstable", "-C", "target-cpu=native", "-C", "opt-level=3"] -
SHARD_SIZE=4194304(for SNARK),SHARD_SIZE=1048576(for STARK)The highest possible setting, giving the fewest shards. Because the compression phase dominates the timing of the SNARK proofs, we need as few shards as possible.
-
SHARD_BATCH_SIZE=0This disables checkpointing making proving faster at the expense of higher memory usage
-
RECONSTRUCT_COMMITMENTS=falseThis setting enables keeping the FFT's data and the entire Merkle Tree in memory without necessity to recompute them in every shard.
-
SHARD_CHUNKING_MULTIPLIER=<32|64>(for SNARK),SHARD_CHUNKING_MULTIPLIER=1(for STARK)This settings is usually selected depending on specific hardware where proving is executed. It is used to determine how many shards get chunked per core on the CPU. For STARK
-
cargo bench --release <...>Make sure to always run in release mode with
--release. Alternatively, specify the proper compiler options viaRUSTFLAGS="-C opt-level=3 <...>",~/.cargo/config.tomlor Cargo profiles -
RUST_LOG=debug(optional)This prints out useful Sphinx metrics, such as cycle counts, iteration speed, proof size, etc. NOTE: This may cause a significant performance degradation, and is only recommended for collecting metrics other than wall clock time.
SNARK proofs
When running any tests or benchmarks that makes Plonk proofs over BN254, the prover leverages some pre-built circuits artifacts. Those circuits artifacts are generated when we release new versions of Sphinx and are automatically downloaded on first use. The current address for downloading the artifacts can be found here, but it should not be necessary to download them manually.
Benchmark individual proofs
In this section we will cover how to run the benchmarks for the individual proofs. The benchmarks are located in the
light-client crate folder. Those benchmarks are associated with programs that are meant to reproduce
a production environment settings. They are meant to measure performance for a complete end-to-end flow.
The numbers we've measured using our production configuration are further detailed in the following section.
Longest chain change
Benchmark that will run a proof generation for the Longest chain program. The program is described in its design document.
On our production configuration, we currently get the following results for SNARK generation for this benchmark:
For SNARKS:
{
"proving_time": 407394,
"verification_time": 4
}
Storage inclusion
Benchmark that will run a proof generation for the SPV program. The program is described in its design document.
On our production configuration, we currently get the following results for SNARK generation for this benchmark:
For SNARKS:
{
"proving_time": 406711,
"verification_time": 4
}
Running the benchmarks
Using Makefile
To ease benchmark run we created a Makefile in the light-client crate folder. Just run:
make benchmark
Info
By default, the proof generated will be a STARK proof. To generate a SNARK proof, use the
MODE=SNARKenvironment variable.
You will then be asked for the name of the benchmark you want to run. Just fill in the one that is of interest to you:
$ make benchmark
Enter benchmark name: longest_chain
...
Manual
Run the following command:
cargo bench --bench execute -- <benchmark_name>
Warning
Make sure to set the environment variables as described in the configuration section.
Interpreting the results
Before delving into the details, please take a look at the cycle tracking documentation from SP1 to get a rough sense of what the numbers mean.
The benchmark will output a lot of information. The most important parts are the following:
Total cycles for the program execution
This value can be found on the following line:
INFO summary: cycles=63736, e2e=2506, khz=25.43, proofSize=2.66 MiB
It contains the total number of cycles needed for the program, the end-to-end time in milliseconds, the frequency of the CPU in kHz, and the size of the proof generated.
Specific cycle count
In the output, you will find a section that looks like this:
DEBUG ┌╴read_inputs
DEBUG └╴9,553 cycles
DEBUG ┌╴verify_merkle_proof
DEBUG └╴40,398 cycles
These specific cycles count are generated by us to track the cost of specific operations in the program.
Proving time
The proving time is an output at the end of a benchmark in the shape of the following data structure, with each time in milliseconds:
{
proving_time: 100000,
verifying_time: 100000
}
Alternative
Another solution to get some information about proving time is to run the tests located in the light-client
crate. They will output the same logs as the benchmarks, only the time necessary to generate a proof will change shape:
Starting generation of Merkle inclusion proof with 18 siblings...
Proving locally
Proving took 5.358508094s
Starting verification of Merkle inclusion proof...
Verification took 805.530068ms
To run the test efficiently, first install
nextest following its documentation. Ensure that you also have the previously described environment variables set, then run the following command:
SHARD_BATCH_SIZE=0 cargo nextest run --verbose --release --profile ci --package kadena-lc --no-capture --all-features
Note
The
--no-captureflag is necessary to see the logs generated by the tests.
Some tests are ignored by default due to heavier resource requirements. To run them, pass --run-ignored all
to nextest.
Benchmark on-chain verification
Our Light Client is able to produce SNARK proofs that can be verified on-chain. This section will cover how to run the benchmarks for the on-chain verification.
To be able to execute such tests the repository contains a project called solidity that is based
off Foundry which demonstrates the Solidity verification using so-called
fixtures (JSON files) containing the proof data (proof itself, public values and verification key) required for running
the verification for both epoch-change and inclusion programs. These fixtures are generated from a SNARK proof generated
by the proof servers, but currently the fixtures generated are meant for simple testing only.
The contracts used for testing can be found in the sphinx-contracts repository which is used as a dependency.
Requirements
Make sure that you have properly set up the sphinx-contracts submodule. If you haven't done so, you can do it by
running the following command:
git submodule update --init --recursive
Run the tests
To run the tests, navigate to the solidity/contracts directory and execute the following command:
cd solidity/contracts && \
forge test
The output should look like this:
% cd solidity/contracts && forge test
[⠊] Compiling...
[⠔] Compiling 30 files with Solc 0.8.26
[⠒] Solc 0.8.26 finished in 1.40s
Compiler run successful!
Ran 8 tests for test/test_lc_proofs.sol:SolidityVerificationTest
[PASS] testFailSmallerConfirmationWorkThreshold1() (gas: 368706)
[PASS] testFailSmallerConfirmationWorkThreshold2() (gas: 359125)
[PASS] testSuccessfulLongestChainVerification() (gas: 414174)
[PASS] testSuccessfulLongestChainVerificationForkCase() (gas: 416590)
[PASS] testSuccessfulSpvVerification() (gas: 432963)
[PASS] testSuccessfulSpvVerificationForkCase() (gas: 435225)
[PASS] testValidLongestChainProofCore() (gas: 2319057)
[PASS] testValidSpvProofCore() (gas: 2319588)
Suite result: ok. 8 passed; 0 failed; 0 skipped; finished in 27.39ms (129.17ms CPU time)
Ran 1 test suite in 87.85ms (27.39ms CPU time): 8 tests passed, 0 failed, 0 skipped (8 total tests)
Currently, the verification of a Plonk proof costs ~318k gas.
Fixture generation
If you wish to either run the tests with custom fixtures or regenerate the existing ones, you can do so by running the
fixture-generator Rust program. This program will run the end-to-end proving (either longest chain or spv) and
export the fixture file to the relevant place (solidity/contracts/src/plonk_fixtures).
To run the fixture-generator for the inclusion program, execute the following command:
RECONSTRUCT_COMMITMENTS=false SHARD_BATCH_SIZE=0 SHARD_CHUNKING_MULTIPLIER=64 SHARD_SIZE=4194304 RUSTFLAGS="-C target-cpu=native -C opt-level=3 --cfg tokio_unstable" cargo run --release --bin generate-fixture -- --program <longest_chain|spv> --language solidity
Tips
Check that the fixtures have been updated by running
git status.
Note
You might be encountering issue with updating
sphinx-contractsFoundry dependency, in this case try manually specifying accessing the submodule via SSH like this:git config submodule.aptos/solidity/contracts/lib/sphinx-contracts.url git@github.com:argumentcomputer/sphinx-contracts
GitHub Release and Patch process
This section is for internal usage. It documents the current release and patch process to ensure that anyone is able to run it.
Release process
The release process is mostly automated through the usage of GitHub Actions.
A release should be initiated through the manually triggered GitHub Action Create release PR. When triggering a release,
the reference base that should be chosen is the dev branch, with a major or minor Semver release type, kadena light-client and the desired release version. The specified release version should follow the Semver standard.
This action pushes a new branch named ``release/kadena-v(whererelease-versionomits the patch number, e.g.1.0) based on the most recent corresponding major/minor release/branch, ordevif none exists. This will be the base of the PR, which will persist across any patches. Then, a PR branch is created off of the base branch calledrelease-pr-kadena-v. A commit is then automatically applied to the PR branch to bump all the Cargo.toml` version of the relevant crates, and the PR is opened. The developer in charge of the release should use this branch to make any necessary updates to the codebase and documentation to have the release ready.
Once all the changes are done, the PR can be merged with a merge commit. This will trigger the Tag release action that is charged with the publication of a release and a tag named kadena-v<release-version>. It will use each commit to create a rich changelog categorized by commit prefix, e.g. feat:, fix:, and chore:.
The base branch should be saved as the release source and in case of any future patches.
Patch process
The patch process is similar to that of a major/minor release.
Create release PR should also be triggered with the patch Semver release type and the desired patch version, e.g. 1.0.1 for a patch to 1.0.0. A PR will be opened from a branch named patch/kadena-v<patch-version> (e.g. v1.0.1) with the base release/kadena-v<release-to-fix> (e.g. v1.0). A commit is automatically applied to bump all the Cargo.toml version of the relevant crates. The developer in charge of the patch should use this branch to make any necessary updates to the codebase and documentation to have the patch ready.
Once all the changes are done, the PR can be squash and merged in release/kadena-v<release-to-fix>. This will trigger the Tag release action that is charged with the publication of a release and a tag named kadena-v<patch-version>.
Finally, the developer may also need to port the relevant changes to dev, such as incrementing the version number for a latest release, so that they are reflected on the latest development stage of the Light Client.